Elasticsearch란?
Elasticsearch는 오픈소스이며 분산, RESTful 검색 및 분석엔진이며 데이터저장소 및 벡터 데이터베이스다.
빠른 검색, 정확도, 강력한 분석을 제공하는게 특징이다.
- 엘라스틱서치 공식 홈페이지
1. 분산 아키텍처
Elasticsearch는 분산형 시스템으로, 데이터가 여러 서버에 분산되어 저장됩니다. 이를 통해 수평적 확장이 가능하고, 대용량 데이터의 저장 및 검색이 용이합니다.(구성에 따라 단일 서버가 될 수 있고, 고가용성에 따른 HA/분산서버/클러스터가 될 수 있습니다.)
2. 문서 기반 저장 방식
Elasticsearch에서는 데이터를 문서(Document)라는 형태로 저장합니다. 문서는 JSON 형식으로 저장되며, 각 문서는 특정 index에 저장됩니다. 이러한 방식은 관계형 데이터베이스의 테이블과 유사하지만, 관계형 데이터베이스와는 달리 데이터 간의 관계를 명시적으로 정의하지 않습니다.
3. 실시간 검색
Elasticsearch는 데이터를 삽입한 후 거의 실시간으로 검색 결과를 제공합니다. 이는 로그나 이벤트 데이터 처리에 매우 유용하며, 실시간 모니터링 시스템에서 중요한 역할을 합니다.
4. 확장성과 내결함성
Elasticsearch는 샤딩(sharding)과 레플리케이션(replication) 기능을 통해 대규모 데이터를 저장할 수 있고, 장애 발생 시에도 시스템이 중단되지 않도록 내결함성을 제공합니다.
Elasticsearch 구성요소(index / Document / Field)
Field
Field는 문서 내 데이터를 저장하는 기본 단위. Key와 Value가 한 쌍으로 이루어져 있습니다.
{
"id": 1, // "id"는 필드, 1은 값
"name": "Laptop", // "name"은 필드, "Laptop"은 값
"price": 999.99, // "price"는 필드, 999.99는 값
"category": "Electronics" // "category"는 필드, "Electronics"는 값
}
Document
Document는 Elasticsearch에서 데이터의 가장 작은 단위. Json 형태로 저장하며 하나의 문서는 하나의 Json 객체
아래 예시가 하나의 Document
{
"id": 1,
"name": "Laptop",
"price": 999.99,
"category": "Electronics"
}
Index
Index는 Elasticsearch에서 데이터를 저장하는 단위. RDBMS에서 테이블과 비슷한 역할이지만 여러 개의 Document를 묶은 단위.
Document1
{
"id": 1,
"name": "Laptop",
"price": 999.99,
"category": "Electronics"
}
Document2
{
"id": 2,
"name": "Smartphone",
"price": 499.99,
"category": "Electronics"
}

Index 다루기
1. Index 조회(본인은 Elasticsearch 설치할 때 Port를 19200으로 수정했다. default Port: 9200)
# Index 전체 목록 조회
$ curl -X GET localhost:19200/_cat/indices?v
# Index 전체 목록 조회(Index 명만 조회)
$ curl -X GET localhost:19200/_cat/indices?h=index
# Index 조회
curl -X GET localhost:19200/<Index 명>
현재는 Index가 없기 때문에 아무런 정보가 뜨지 않는다.
2. Index 생성
# Index 생성(?pretty를 붙이면 json 형태로 보여준다)
$ curl -X PUT localhost:19200/products
$ curl -X PUT localhost:19200/products2?pretty
2-1. Index 조회
# Index 조회
$ curl -X GET localhost:19200/products
# Index 조회(output을 예쁘게)
$ curl -X GET localhost:19200/products?pretty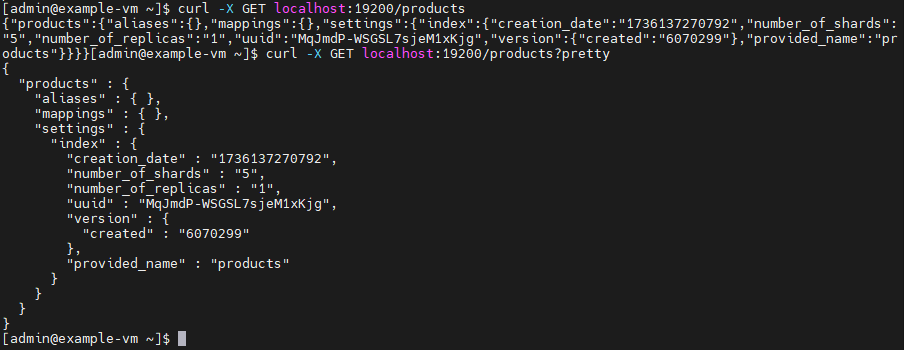
2-2. Index 전체 조회
# Index 전체 목록 조회
$ curl -X GET localhost:19200/_cat/indices?v
# Index 전체 목록 조회(Index 명만 조회)
$ curl -X GET localhost:19200/_cat/indices?h=index
3. Index 삭제
# Index 삭제
$ curl -X DELETE localhost:19200/products2

4. Index 데이터 삽입
$ curl -X POST "localhost:19200/products/_doc?/pretty" -H 'Content-Type: application/json' -d '
{
"id": 1,
"name": "Laptop",
"price": 999.99,
"category": "Electronics"
}'
또는
$ curl -X PUT "localhost:9200/products/_doc/1" -H 'Content-Type: application/json' -d '
{
"id": 1,
"name": "Laptop",
"price": 999.99,
"category": "Electronics"
}'
4.1 삽입한 데이터 확인
$ curl -X GET "localhost:19200/products/_doc/1?pretty"
ELK/EFK
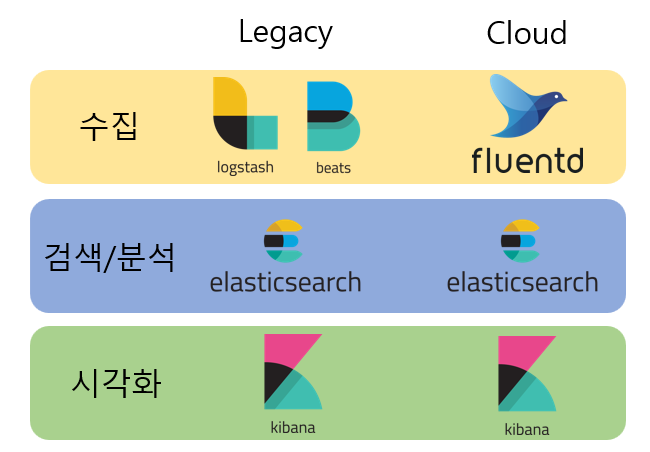
Elasticsearch는 주로 효율적인 검색과 대용량 데이터 분석에 많이 쓴다.
로그 검색 및 분석에 많이 사용되는데 로그 수집기인 Logstash, 시각화 도구인 Kibana와 같이 사용하여 ELK라고도 부른다. 클라우드에서는 클러스터, Pod의 로그 수집기인 Fluentd를 사용해 EFK(Elasticsearch, Fluentd, Kibana)도 많이 사용한다.
'Linux > RHEL' 카테고리의 다른 글
| Rocky Linux8 엘라스틱서치 Elasticsearch 버전 업그레이드 (0) | 2025.01.08 |
|---|---|
| Rocky LInux8 Elasticsearch Install 설치 systemctl 등록 (0) | 2024.12.19 |
| Rocky Linux8 Grafana 업그레이드 (0) | 2024.12.18 |
| Rocky Linux8 Grafana 7.1.5 설치 (0) | 2024.12.13 |
| RHEL8 ISO 파일을 이용하여 Local Repository 구성하기 (0) | 2022.08.02 |



